


使用向量化環境和領域隨機化訓練 A2C¶
注意事項¶
如果您遇到類似以下註解在 multiprocessing/spawn.py 中提出的 RuntimeError,請使用 if__name__ == '__main__' 將程式碼從 gym.vector.make= 或 gym.vector.AsyncVectorEnv 包裹到程式碼的結尾。
在 目前的 程序 完成 其 啟動 階段 之前, 已 嘗試 啟動 一個 新的 程序。
簡介¶
在本教學中,您將學習如何使用向量化環境來訓練優勢演員-評論家智能體。我們將使用 A2C,它是 A3C 演算法 [1] 的同步版本。
向量化環境 [3] 可以透過允許多個相同環境的實例並行運行(在多個 CPU 上),來幫助實現更快且更穩健的訓練。這可以顯著降低變異數,從而加速訓練。
我們將從頭開始實作優勢演員-評論家,以了解如何將批次狀態饋送到您的網路中,以獲得動作向量(每個環境一個動作),並計算演員和評論家在轉換小批次上的損失。每個小批次包含一個採樣階段的轉換:在 n_envs 個環境中並行執行 n_steps_per_update 步(將兩者相乘即可得到一個小批次中的轉換次數)。在每個採樣階段之後,計算損失並執行一個梯度步驟。為了計算優勢,我們將使用廣義優勢估計 (GAE) 方法 [2],該方法平衡了優勢估計的變異數和偏差之間的權衡。
A2C 智能體類別使用輸入狀態的特徵數量、智能體可以採取的動作數量、學習率以及並行運行的環境數量進行初始化,以收集經驗。定義了演員和評論家網路,並初始化了它們各自的優化器。網路的前向傳遞接收批次狀態向量,並返回狀態值張量和動作 logits 張量。 select_action 方法返回所選動作、這些動作的 log-probs 以及每個動作的狀態值的元組。此外,它還返回策略分佈的熵,稍後將從損失中減去熵(使用加權因子 ent_coef)以鼓勵探索。
get_losses 函數計算演員和評論家網路的損失(使用 GAE),然後使用 update_parameters 函數更新這些損失。
# Author: Till Zemann
# License: MIT License
from __future__ import annotations
import os
import matplotlib.pyplot as plt
import numpy as np
import torch
import torch.nn as nn
from torch import optim
from tqdm import tqdm
import gymnasium as gym
優勢演員-評論家 (A2C)¶
演員-評論家結合了基於價值和基於策略的方法的元素。在 A2C 中,智能體有兩個獨立的神經網路:一個評論家網路,用於估計狀態價值函數;以及一個演員網路,用於輸出所有動作的類別機率分佈的 logits。訓練評論家網路以最小化預測狀態值與智能體收到的實際回報之間的均方誤差(這相當於最小化平方優勢,因為動作的優勢是回報與狀態價值之間的差異:A(s,a) = Q(s,a) - V(s)。訓練演員網路以透過根據評論家網路選擇具有高期望值的動作來最大化期望回報。
本教學的重點將不會放在 A2C 本身的細節上。相反,本教學將重點介紹如何使用向量化環境和領域隨機化來加速 A2C(以及其他強化學習演算法)的訓練過程。
class A2C(nn.Module):
"""
(Synchronous) Advantage Actor-Critic agent class
Args:
n_features: The number of features of the input state.
n_actions: The number of actions the agent can take.
device: The device to run the computations on (running on a GPU might be quicker for larger Neural Nets,
for this code CPU is totally fine).
critic_lr: The learning rate for the critic network (should usually be larger than the actor_lr).
actor_lr: The learning rate for the actor network.
n_envs: The number of environments that run in parallel (on multiple CPUs) to collect experiences.
"""
def __init__(
self,
n_features: int,
n_actions: int,
device: torch.device,
critic_lr: float,
actor_lr: float,
n_envs: int,
) -> None:
"""Initializes the actor and critic networks and their respective optimizers."""
super().__init__()
self.device = device
self.n_envs = n_envs
critic_layers = [
nn.Linear(n_features, 32),
nn.ReLU(),
nn.Linear(32, 32),
nn.ReLU(),
nn.Linear(32, 1), # estimate V(s)
]
actor_layers = [
nn.Linear(n_features, 32),
nn.ReLU(),
nn.Linear(32, 32),
nn.ReLU(),
nn.Linear(
32, n_actions
), # estimate action logits (will be fed into a softmax later)
]
# define actor and critic networks
self.critic = nn.Sequential(*critic_layers).to(self.device)
self.actor = nn.Sequential(*actor_layers).to(self.device)
# define optimizers for actor and critic
self.critic_optim = optim.RMSprop(self.critic.parameters(), lr=critic_lr)
self.actor_optim = optim.RMSprop(self.actor.parameters(), lr=actor_lr)
def forward(self, x: np.ndarray) -> tuple[torch.Tensor, torch.Tensor]:
"""
Forward pass of the networks.
Args:
x: A batched vector of states.
Returns:
state_values: A tensor with the state values, with shape [n_envs,].
action_logits_vec: A tensor with the action logits, with shape [n_envs, n_actions].
"""
x = torch.Tensor(x).to(self.device)
state_values = self.critic(x) # shape: [n_envs,]
action_logits_vec = self.actor(x) # shape: [n_envs, n_actions]
return (state_values, action_logits_vec)
def select_action(
self, x: np.ndarray
) -> tuple[torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor]:
"""
Returns a tuple of the chosen actions and the log-probs of those actions.
Args:
x: A batched vector of states.
Returns:
actions: A tensor with the actions, with shape [n_steps_per_update, n_envs].
action_log_probs: A tensor with the log-probs of the actions, with shape [n_steps_per_update, n_envs].
state_values: A tensor with the state values, with shape [n_steps_per_update, n_envs].
"""
state_values, action_logits = self.forward(x)
action_pd = torch.distributions.Categorical(
logits=action_logits
) # implicitly uses softmax
actions = action_pd.sample()
action_log_probs = action_pd.log_prob(actions)
entropy = action_pd.entropy()
return (actions, action_log_probs, state_values, entropy)
def get_losses(
self,
rewards: torch.Tensor,
action_log_probs: torch.Tensor,
value_preds: torch.Tensor,
entropy: torch.Tensor,
masks: torch.Tensor,
gamma: float,
lam: float,
ent_coef: float,
device: torch.device,
) -> tuple[torch.Tensor, torch.Tensor]:
"""
Computes the loss of a minibatch (transitions collected in one sampling phase) for actor and critic
using Generalized Advantage Estimation (GAE) to compute the advantages (https://arxiv.org/abs/1506.02438).
Args:
rewards: A tensor with the rewards for each time step in the episode, with shape [n_steps_per_update, n_envs].
action_log_probs: A tensor with the log-probs of the actions taken at each time step in the episode, with shape [n_steps_per_update, n_envs].
value_preds: A tensor with the state value predictions for each time step in the episode, with shape [n_steps_per_update, n_envs].
masks: A tensor with the masks for each time step in the episode, with shape [n_steps_per_update, n_envs].
gamma: The discount factor.
lam: The GAE hyperparameter. (lam=1 corresponds to Monte-Carlo sampling with high variance and no bias,
and lam=0 corresponds to normal TD-Learning that has a low variance but is biased
because the estimates are generated by a Neural Net).
device: The device to run the computations on (e.g. CPU or GPU).
Returns:
critic_loss: The critic loss for the minibatch.
actor_loss: The actor loss for the minibatch.
"""
T = len(rewards)
advantages = torch.zeros(T, self.n_envs, device=device)
# compute the advantages using GAE
gae = 0.0
for t in reversed(range(T - 1)):
td_error = (
rewards[t] + gamma * masks[t] * value_preds[t + 1] - value_preds[t]
)
gae = td_error + gamma * lam * masks[t] * gae
advantages[t] = gae
# calculate the loss of the minibatch for actor and critic
critic_loss = advantages.pow(2).mean()
# give a bonus for higher entropy to encourage exploration
actor_loss = (
-(advantages.detach() * action_log_probs).mean() - ent_coef * entropy.mean()
)
return (critic_loss, actor_loss)
def update_parameters(
self, critic_loss: torch.Tensor, actor_loss: torch.Tensor
) -> None:
"""
Updates the parameters of the actor and critic networks.
Args:
critic_loss: The critic loss.
actor_loss: The actor loss.
"""
self.critic_optim.zero_grad()
critic_loss.backward()
self.critic_optim.step()
self.actor_optim.zero_grad()
actor_loss.backward()
self.actor_optim.step()
使用向量化環境¶
當您僅在一個 epoch 上計算兩個神經網路的損失時,它可能具有很高的變異數。透過向量化環境,我們可以並行處理 n_envs 個環境,從而獲得高達線性的加速(這意味著理論上,我們收集樣本的速度快了 n_envs 倍),我們可以使用它來計算當前策略和評論家網路的損失。當我們使用更多樣本來計算損失時,它將具有較低的變異數,因此可以更快地學習。
A2C 是一種同步方法,這意味著網路的參數更新是確定性地發生的(在每個採樣階段之後),但我們仍然可以利用非同步向量化環境來產生多個程序以進行並行環境執行。
建立向量化環境最簡單的方法是呼叫 gym.vector.make,它會建立同一個環境的多個實例。
envs = gym.vector.make("LunarLander-v3", num_envs=3, max_episode_steps=600)
領域隨機化¶
如果我們想要隨機化環境以進行訓練,以獲得更穩健的智能體(可以處理環境的不同參數化,因此可能具有更高的泛化程度),我們可以手動設定所需的參數,或使用偽隨機數產生器來產生它們。
手動設定 3 個具有不同參數的並行 'LunarLander-v3' 環境
envs = gym.vector.AsyncVectorEnv(
[
lambda: gym.make(
"LunarLander-v3",
gravity=-10.0,
enable_wind=True,
wind_power=15.0,
turbulence_power=1.5,
max_episode_steps=600,
),
lambda: gym.make(
"LunarLander-v3",
gravity=-9.8,
enable_wind=True,
wind_power=10.0,
turbulence_power=1.3,
max_episode_steps=600,
),
lambda: gym.make(
"LunarLander-v3", gravity=-7.0, enable_wind=False, max_episode_steps=600
),
]
)
隨機產生 3 個並行 'LunarLander-v3' 環境的參數,使用 np.clip 以保持在建議的參數空間內
envs = gym.vector.AsyncVectorEnv(
[
lambda: gym.make(
"LunarLander-v3",
gravity=np.clip(
np.random.normal(loc=-10.0, scale=1.0), a_min=-11.99, a_max=-0.01
),
enable_wind=np.random.choice([True, False]),
wind_power=np.clip(
np.random.normal(loc=15.0, scale=1.0), a_min=0.01, a_max=19.99
),
turbulence_power=np.clip(
np.random.normal(loc=1.5, scale=0.5), a_min=0.01, a_max=1.99
),
max_episode_steps=600,
)
for i in range(3)
]
)
在此,我們使用常態分佈,以環境的標準參數化作為平均值和任意標準差(scale)。根據問題的不同,您可以嘗試更高的變異數並使用不同的分佈。
如果您在整個訓練時間內都在相同的 n_envs 個環境上進行訓練,並且 n_envs 是一個相對較低的數字(相對於環境的複雜程度而言),您可能仍然會對您選擇的特定參數化產生一些過度擬合。為了減輕這種情況,您可以選擇大量隨機參數化的環境,或者每隔幾個採樣階段重新建立您的環境,以產生一組新的偽隨機參數。
設定¶
# environment hyperparams
n_envs = 10
n_updates = 1000
n_steps_per_update = 128
randomize_domain = False
# agent hyperparams
gamma = 0.999
lam = 0.95 # hyperparameter for GAE
ent_coef = 0.01 # coefficient for the entropy bonus (to encourage exploration)
actor_lr = 0.001
critic_lr = 0.005
# Note: the actor has a slower learning rate so that the value targets become
# more stationary and are theirfore easier to estimate for the critic
# environment setup
if randomize_domain:
envs = gym.vector.AsyncVectorEnv(
[
lambda: gym.make(
"LunarLander-v3",
gravity=np.clip(
np.random.normal(loc=-10.0, scale=1.0), a_min=-11.99, a_max=-0.01
),
enable_wind=np.random.choice([True, False]),
wind_power=np.clip(
np.random.normal(loc=15.0, scale=1.0), a_min=0.01, a_max=19.99
),
turbulence_power=np.clip(
np.random.normal(loc=1.5, scale=0.5), a_min=0.01, a_max=1.99
),
max_episode_steps=600,
)
for i in range(n_envs)
]
)
else:
envs = gym.vector.make("LunarLander-v3", num_envs=n_envs, max_episode_steps=600)
obs_shape = envs.single_observation_space.shape[0]
action_shape = envs.single_action_space.n
# set the device
use_cuda = False
if use_cuda:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
else:
device = torch.device("cpu")
# init the agent
agent = A2C(obs_shape, action_shape, device, critic_lr, actor_lr, n_envs)
訓練 A2C 智能體¶
對於我們的訓練迴圈,我們使用 RecordEpisodeStatistics 封裝器來記錄 episode 長度和回報,並且我們還儲存損失和熵,以便在智能體完成訓練後繪製它們。
您可能會注意到,我們不像通常那樣在每個 episode 開始時重置向量化環境。這是因為每個環境在 episode 結束時會自動重置(由於隨機種子,每個環境完成一個 episode 所需的時間步數不同)。因此,我們也沒有在 episodes 中收集資料,而是僅在每個環境中執行一定數量的步驟 (n_steps_per_update)(例如,這可能意味著我們執行 20 個時間步來完成一個 episode,然後使用剩餘的時間步開始一個新的 episode)。
# create a wrapper environment to save episode returns and episode lengths
envs_wrapper = gym.wrappers.RecordEpisodeStatistics(envs, deque_size=n_envs * n_updates)
critic_losses = []
actor_losses = []
entropies = []
# use tqdm to get a progress bar for training
for sample_phase in tqdm(range(n_updates)):
# we don't have to reset the envs, they just continue playing
# until the episode is over and then reset automatically
# reset lists that collect experiences of an episode (sample phase)
ep_value_preds = torch.zeros(n_steps_per_update, n_envs, device=device)
ep_rewards = torch.zeros(n_steps_per_update, n_envs, device=device)
ep_action_log_probs = torch.zeros(n_steps_per_update, n_envs, device=device)
masks = torch.zeros(n_steps_per_update, n_envs, device=device)
# at the start of training reset all envs to get an initial state
if sample_phase == 0:
states, info = envs_wrapper.reset(seed=42)
# play n steps in our parallel environments to collect data
for step in range(n_steps_per_update):
# select an action A_{t} using S_{t} as input for the agent
actions, action_log_probs, state_value_preds, entropy = agent.select_action(
states
)
# perform the action A_{t} in the environment to get S_{t+1} and R_{t+1}
states, rewards, terminated, truncated, infos = envs_wrapper.step(
actions.cpu().numpy()
)
ep_value_preds[step] = torch.squeeze(state_value_preds)
ep_rewards[step] = torch.tensor(rewards, device=device)
ep_action_log_probs[step] = action_log_probs
# add a mask (for the return calculation later);
# for each env the mask is 1 if the episode is ongoing and 0 if it is terminated (not by truncation!)
masks[step] = torch.tensor([not term for term in terminated])
# calculate the losses for actor and critic
critic_loss, actor_loss = agent.get_losses(
ep_rewards,
ep_action_log_probs,
ep_value_preds,
entropy,
masks,
gamma,
lam,
ent_coef,
device,
)
# update the actor and critic networks
agent.update_parameters(critic_loss, actor_loss)
# log the losses and entropy
critic_losses.append(critic_loss.detach().cpu().numpy())
actor_losses.append(actor_loss.detach().cpu().numpy())
entropies.append(entropy.detach().mean().cpu().numpy())
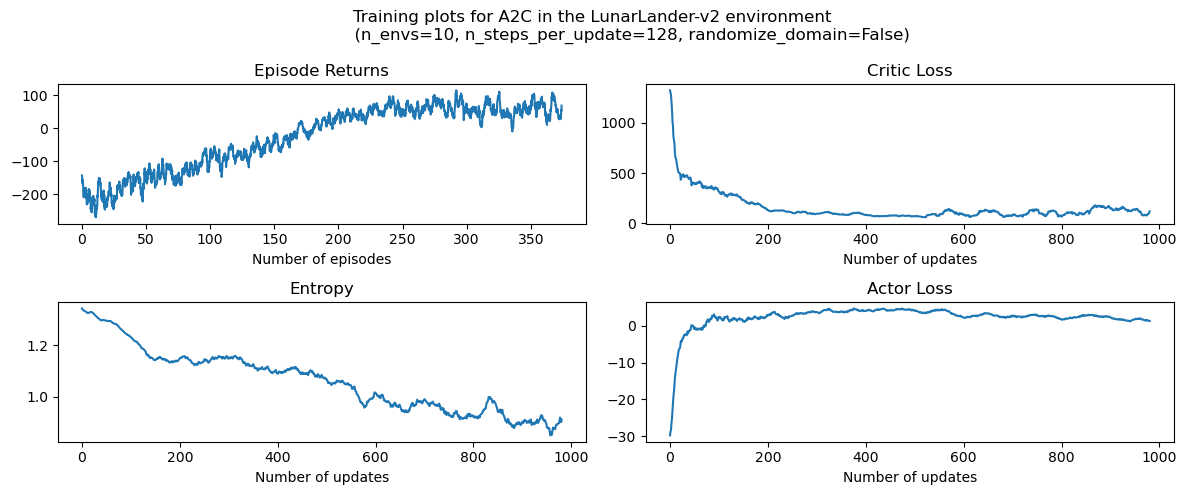
繪圖¶
""" plot the results """
# %matplotlib inline
rolling_length = 20
fig, axs = plt.subplots(nrows=2, ncols=2, figsize=(12, 5))
fig.suptitle(
f"Training plots for {agent.__class__.__name__} in the LunarLander-v3 environment \n \
(n_envs={n_envs}, n_steps_per_update={n_steps_per_update}, randomize_domain={randomize_domain})"
)
# episode return
axs[0][0].set_title("Episode Returns")
episode_returns_moving_average = (
np.convolve(
np.array(envs_wrapper.return_queue).flatten(),
np.ones(rolling_length),
mode="valid",
)
/ rolling_length
)
axs[0][0].plot(
np.arange(len(episode_returns_moving_average)) / n_envs,
episode_returns_moving_average,
)
axs[0][0].set_xlabel("Number of episodes")
# entropy
axs[1][0].set_title("Entropy")
entropy_moving_average = (
np.convolve(np.array(entropies), np.ones(rolling_length), mode="valid")
/ rolling_length
)
axs[1][0].plot(entropy_moving_average)
axs[1][0].set_xlabel("Number of updates")
# critic loss
axs[0][1].set_title("Critic Loss")
critic_losses_moving_average = (
np.convolve(
np.array(critic_losses).flatten(), np.ones(rolling_length), mode="valid"
)
/ rolling_length
)
axs[0][1].plot(critic_losses_moving_average)
axs[0][1].set_xlabel("Number of updates")
# actor loss
axs[1][1].set_title("Actor Loss")
actor_losses_moving_average = (
np.convolve(np.array(actor_losses).flatten(), np.ones(rolling_length), mode="valid")
/ rolling_length
)
axs[1][1].plot(actor_losses_moving_average)
axs[1][1].set_xlabel("Number of updates")
plt.tight_layout()
plt.show()
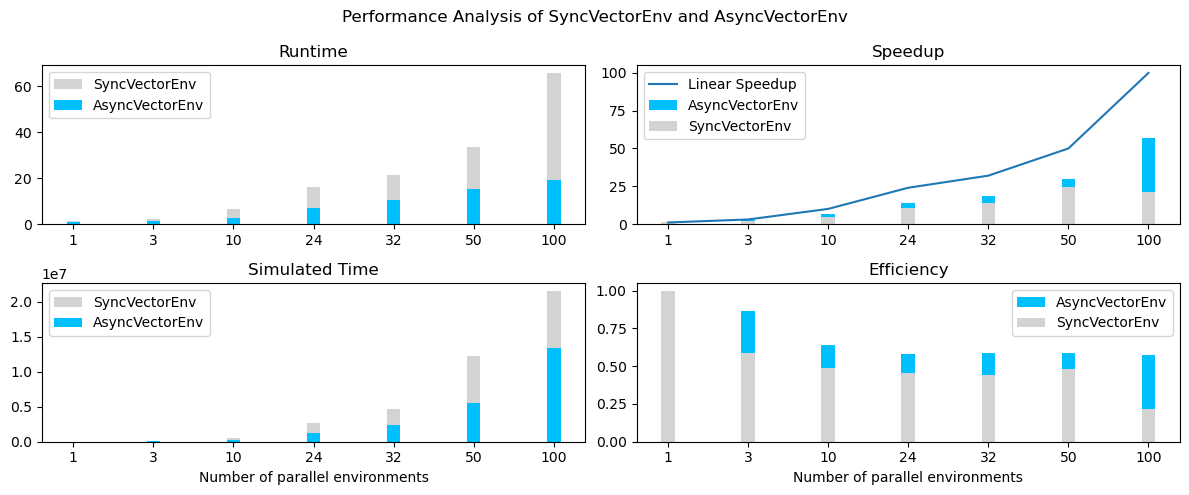
同步和非同步向量化環境的效能分析¶
與同步環境相比,非同步環境可以帶來更快的訓練時間和更高的資料收集加速。這是因為非同步環境允許多個智能體並行地與其環境互動,而同步環境則串行地運行多個環境。這使得非同步環境具有更高的效率和更快的訓練時間。
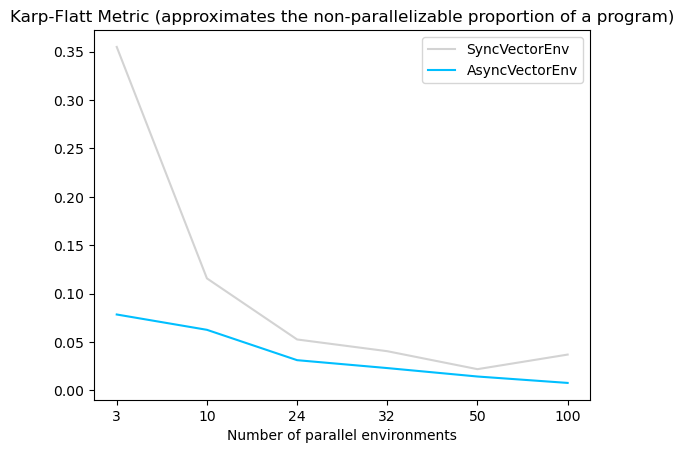
根據 Karp-Flatt 指標(一種用於並行計算的指標,用於估計在擴展並行程序數量時的加速限制,此處為環境數量),非同步環境的估計最大加速為 57,而同步環境的估計最大加速為 21。這表明,與同步環境相比,非同步環境具有顯著更快的訓練時間(請參閱圖表)。
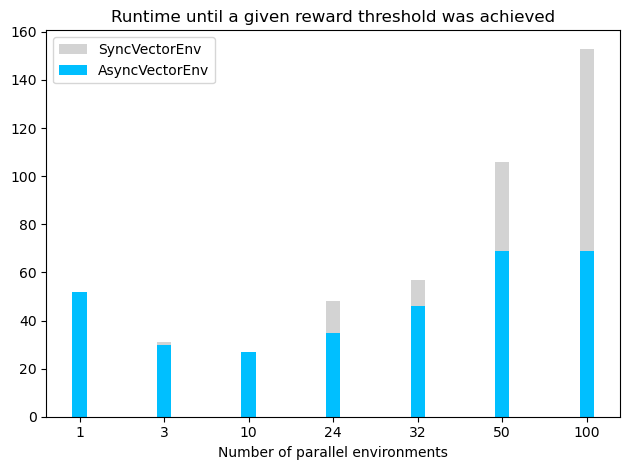
然而,重要的是要注意,在環境數量達到一定程度後,增加並行向量化環境的數量可能會導致訓練時間變慢(請參閱下面的圖表,其中智能體被訓練直到平均訓練回報高於 -120)。訓練時間變慢可能是因為在環境數量相對較少時(尤其是在環境不是很複雜的情況下),環境的梯度就已經足夠好了。在這種情況下,增加環境數量並不會提高學習速度,實際上會增加運行時間,這可能是由於計算梯度需要額外的時間。對於 LunarLander-v3,效能最佳的配置使用了具有 10 個並行環境的 AsyncVectorEnv,但複雜度更高的環境可能需要更多並行環境才能實現最佳效能。
儲存/載入權重¶
save_weights = False
load_weights = False
actor_weights_path = "weights/actor_weights.h5"
critic_weights_path = "weights/critic_weights.h5"
if not os.path.exists("weights"):
os.mkdir("weights")
""" save network weights """
if save_weights:
torch.save(agent.actor.state_dict(), actor_weights_path)
torch.save(agent.critic.state_dict(), critic_weights_path)
""" load network weights """
if load_weights:
agent = A2C(obs_shape, action_shape, device, critic_lr, actor_lr)
agent.actor.load_state_dict(torch.load(actor_weights_path))
agent.critic.load_state_dict(torch.load(critic_weights_path))
agent.actor.eval()
agent.critic.eval()
展示智能體¶
""" play a couple of showcase episodes """
n_showcase_episodes = 3
for episode in range(n_showcase_episodes):
print(f"starting episode {episode}...")
# create a new sample environment to get new random parameters
if randomize_domain:
env = gym.make(
"LunarLander-v3",
render_mode="human",
gravity=np.clip(
np.random.normal(loc=-10.0, scale=2.0), a_min=-11.99, a_max=-0.01
),
enable_wind=np.random.choice([True, False]),
wind_power=np.clip(
np.random.normal(loc=15.0, scale=2.0), a_min=0.01, a_max=19.99
),
turbulence_power=np.clip(
np.random.normal(loc=1.5, scale=1.0), a_min=0.01, a_max=1.99
),
max_episode_steps=500,
)
else:
env = gym.make("LunarLander-v3", render_mode="human", max_episode_steps=500)
# get an initial state
state, info = env.reset()
# play one episode
done = False
while not done:
# select an action A_{t} using S_{t} as input for the agent
with torch.no_grad():
action, _, _, _ = agent.select_action(state[None, :])
# perform the action A_{t} in the environment to get S_{t+1} and R_{t+1}
state, reward, terminated, truncated, info = env.step(action.item())
# update if the environment is done
done = terminated or truncated
env.close()
親自嘗試遊玩環境¶
# from gymnasium.utils.play import play
#
# play(gym.make('LunarLander-v3', render_mode='rgb_array'),
# keys_to_action={'w': 2, 'a': 1, 'd': 3}, noop=0)
參考文獻¶
[1] V. Mnih, A. P. Badia, M. Mirza, A. Graves, T. P. Lillicrap, T. Harley, D. Silver, K. Kavukcuoglu. “用於深度強化學習的非同步方法” ICML (2016)。
[2] J. Schulman, P. Moritz, S. Levine, M. Jordan 和 P. Abbeel。 “使用廣義優勢估計進行高維度連續控制。” ICLR (2016)。
[3] Gymnasium 文件:向量化環境。(網址:https://gymnasium.dev.org.tw/api/vector/)