


製作您自己的自訂環境¶
本文件概述了如何建立新環境,以及 Gymnasium 中包含的,為建立新環境而設計的相關實用封裝器、工具和測試。
設定¶
推薦解決方案¶
請依照 pipx 文件 安裝
pipx。然後安裝 Copier
pipx install copier
替代解決方案¶
使用 Pip 或 Conda 安裝 Copier
pip install copier
或
conda install -c conda-forge copier
產生您的環境¶
您可以執行以下命令來檢查 Copier 是否已正確安裝,該命令應輸出版本號碼
copier --version
然後您可以直接執行以下命令,並將字串 path/to/directory 替換為您想要建立新專案的目錄路徑。
copier copy https://github.com/Farama-Foundation/gymnasium-env-template.git "path/to/directory"
回答問題,完成後您應該會得到如下的專案結構
.
├── gymnasium_env
│ ├── envs
│ │ ├── grid_world.py
│ │ └── __init__.py
│ ├── __init__.py
│ └── wrappers
│ ├── clip_reward.py
│ ├── discrete_actions.py
│ ├── __init__.py
│ ├── reacher_weighted_reward.py
│ └── relative_position.py
├── LICENSE
├── pyproject.toml
└── README.md
繼承 gymnasium.Env 子類別¶
在學習如何建立自己的環境之前,您應該查看 Gymnasium API 的文件。
為了說明繼承 gymnasium.Env 子類別的過程,我們將實作一個非常簡單的遊戲,稱為 GridWorldEnv。我們將在 gymnasium_env/envs/grid_world.py 中編寫自訂環境的程式碼。該環境由固定大小的二維正方形網格組成(在建構期間透過 size 參數指定)。代理可以在每個時間步在網格單元之間垂直或水平移動。代理的目標是導航到網格上的目標,該目標在回合開始時隨機放置。
觀察提供目標和代理的位置。
我們的環境中有 4 個動作,分別對應於「右」、「上」、「左」和「下」的移動。
一旦代理導航到目標所在的網格單元,就會發出完成訊號。
獎勵是二元且稀疏的,這意味著立即獎勵始終為零,除非代理已到達目標,則為 1。
此環境中的一個回合(size=5)可能如下所示
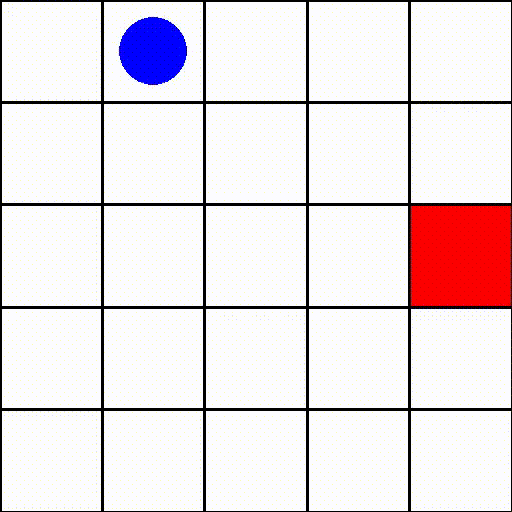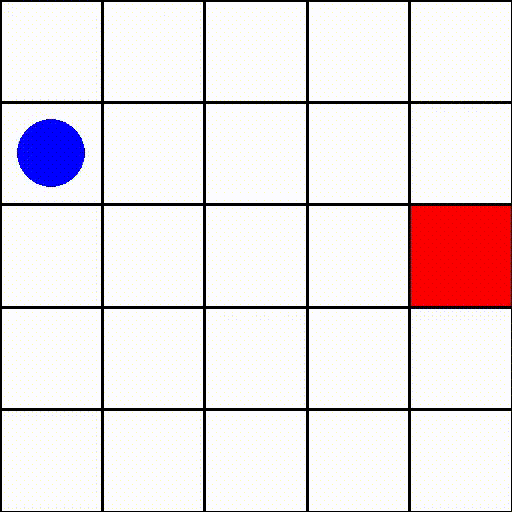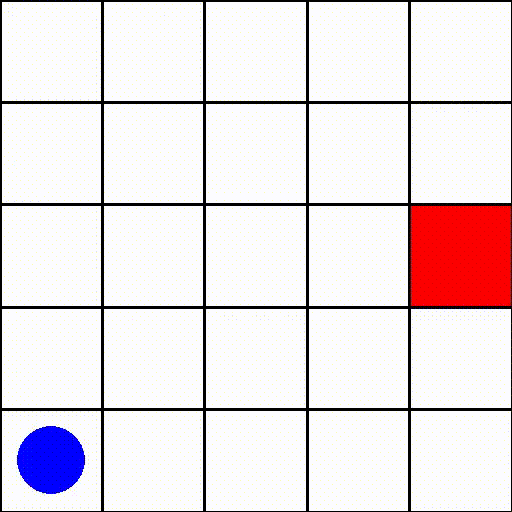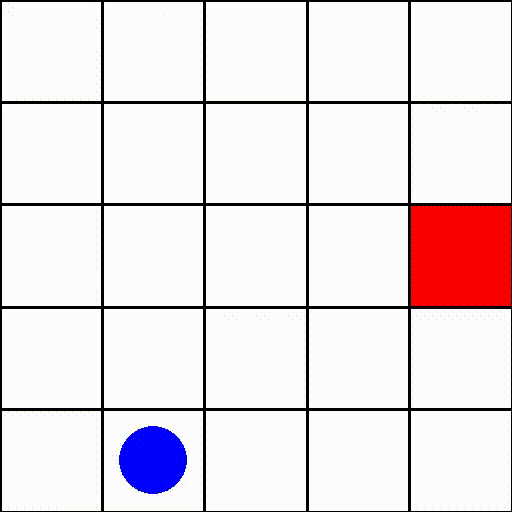
其中藍點是代理,紅方塊代表目標。
讓我們逐段查看 GridWorldEnv 的原始碼
宣告與初始化¶
我們的自訂環境將繼承自抽象類別 gymnasium.Env。您不應忘記將 metadata 屬性新增至您的類別。在那裡,您應該指定您的環境支援的渲染模式(例如,"human"、"rgb_array"、"ansi")以及環境應渲染的影格率。每個環境都應支援 None 作為渲染模式;您無需將其新增至 metadata 中。在 GridWorldEnv 中,我們將支援 “rgb_array” 和 “human” 模式,並以 4 FPS 渲染。
我們環境的 __init__ 方法將接受整數 size,它決定了正方形網格的大小。我們將設定一些用於渲染的變數,並定義 self.observation_space 和 self.action_space。在我們的例子中,觀察應提供有關代理和目標在二維網格上的位置資訊。我們將選擇以字典的形式表示觀察,並使用鍵 "agent" 和 "target"。觀察可能如下所示:{"agent": array([1, 0]), "target": array([0, 3])}。由於我們的環境中有 4 個動作(“right”、“up”、“left”、“down”),我們將使用 Discrete(4) 作為動作空間。以下是 GridWorldEnv 的宣告和 __init__ 的實作
# gymnasium_env/envs/grid_world.py
from enum import Enum
import numpy as np
import pygame
import gymnasium as gym
from gymnasium import spaces
class Actions(Enum):
RIGHT = 0
UP = 1
LEFT = 2
DOWN = 3
class GridWorldEnv(gym.Env):
metadata = {"render_modes": ["human", "rgb_array"], "render_fps": 4}
def __init__(self, render_mode=None, size=5):
self.size = size # The size of the square grid
self.window_size = 512 # The size of the PyGame window
# Observations are dictionaries with the agent's and the target's location.
# Each location is encoded as an element of {0, ..., `size`}^2, i.e. MultiDiscrete([size, size]).
self.observation_space = spaces.Dict(
{
"agent": spaces.Box(0, size - 1, shape=(2,), dtype=int),
"target": spaces.Box(0, size - 1, shape=(2,), dtype=int),
}
)
self._agent_location = np.array([-1, -1], dtype=int)
self._target_location = np.array([-1, -1], dtype=int)
# We have 4 actions, corresponding to "right", "up", "left", "down"
self.action_space = spaces.Discrete(4)
"""
The following dictionary maps abstract actions from `self.action_space` to
the direction we will walk in if that action is taken.
i.e. 0 corresponds to "right", 1 to "up" etc.
"""
self._action_to_direction = {
Actions.RIGHT.value: np.array([1, 0]),
Actions.UP.value: np.array([0, 1]),
Actions.LEFT.value: np.array([-1, 0]),
Actions.DOWN.value: np.array([0, -1]),
}
assert render_mode is None or render_mode in self.metadata["render_modes"]
self.render_mode = render_mode
"""
If human-rendering is used, `self.window` will be a reference
to the window that we draw to. `self.clock` will be a clock that is used
to ensure that the environment is rendered at the correct framerate in
human-mode. They will remain `None` until human-mode is used for the
first time.
"""
self.window = None
self.clock = None
從環境狀態建構觀察¶
由於我們需要在 reset 和 step 中計算觀察,因此通常方便有一個(私有)方法 _get_obs 將環境的狀態轉換為觀察。但是,這不是強制性的,您也可以在 reset 和 step 中分別計算觀察
def _get_obs(self):
return {"agent": self._agent_location, "target": self._target_location}
我們也可以為 step 和 reset 返回的輔助資訊實作類似的方法。在我們的例子中,我們希望提供代理和目標之間的曼哈頓距離
def _get_info(self):
return {
"distance": np.linalg.norm(
self._agent_location - self._target_location, ord=1
)
}
通常,info 也會包含一些僅在 step 方法內可用的資料(例如,個別獎勵項)。在這種情況下,我們必須更新 step 中 _get_info 返回的字典。
重置¶
將呼叫 reset 方法以啟動新回合。您可以假設在呼叫 reset 之前不會呼叫 step 方法。此外,每當發出完成訊號時,都應呼叫 reset。使用者可以將 seed 關鍵字傳遞給 reset,以將環境使用的任何隨機數字產生器初始化為確定性狀態。建議使用環境基底類別 gymnasium.Env 提供的隨機數字產生器 self.np_random。如果您僅使用此 RNG,則無需太擔心設定種子,*但您需要記住呼叫 ``super().reset(seed=seed)``* 以確保 gymnasium.Env 正確地為 RNG 設定種子。完成此操作後,我們可以隨機設定環境的狀態。在我們的例子中,我們隨機選擇代理的位置和隨機樣本目標位置,直到它不與代理的位置重合。
reset 方法應返回初始觀察和一些輔助資訊的元組。我們可以為此使用我們先前實作的 _get_obs 和 _get_info 方法
def reset(self, seed=None, options=None):
# We need the following line to seed self.np_random
super().reset(seed=seed)
# Choose the agent's location uniformly at random
self._agent_location = self.np_random.integers(0, self.size, size=2, dtype=int)
# We will sample the target's location randomly until it does not coincide with the agent's location
self._target_location = self._agent_location
while np.array_equal(self._target_location, self._agent_location):
self._target_location = self.np_random.integers(
0, self.size, size=2, dtype=int
)
observation = self._get_obs()
info = self._get_info()
if self.render_mode == "human":
self._render_frame()
return observation, info
步進¶
step 方法通常包含您環境的大部分邏輯。它接受一個 action,計算應用該動作後環境的狀態,並返回 5 元組 (observation, reward, terminated, truncated, info)。請參閱 gymnasium.Env.step()。一旦計算出環境的新狀態,我們可以檢查它是否為終止狀態,並相應地設定 done。由於我們在 GridWorldEnv 中使用稀疏二元獎勵,因此一旦我們知道 done,計算 reward 就變得非常簡單。為了收集 observation 和 info,我們可以再次使用 _get_obs 和 _get_info
def step(self, action):
# Map the action (element of {0,1,2,3}) to the direction we walk in
direction = self._action_to_direction[action]
# We use `np.clip` to make sure we don't leave the grid
self._agent_location = np.clip(
self._agent_location + direction, 0, self.size - 1
)
# An episode is done iff the agent has reached the target
terminated = np.array_equal(self._agent_location, self._target_location)
reward = 1 if terminated else 0 # Binary sparse rewards
observation = self._get_obs()
info = self._get_info()
if self.render_mode == "human":
self._render_frame()
return observation, reward, terminated, False, info
渲染¶
在此,我們使用 PyGame 進行渲染。Gymnasium 隨附的許多環境中都使用了類似的渲染方法,您可以將其用作您自己環境的骨架
def render(self):
if self.render_mode == "rgb_array":
return self._render_frame()
def _render_frame(self):
if self.window is None and self.render_mode == "human":
pygame.init()
pygame.display.init()
self.window = pygame.display.set_mode(
(self.window_size, self.window_size)
)
if self.clock is None and self.render_mode == "human":
self.clock = pygame.time.Clock()
canvas = pygame.Surface((self.window_size, self.window_size))
canvas.fill((255, 255, 255))
pix_square_size = (
self.window_size / self.size
) # The size of a single grid square in pixels
# First we draw the target
pygame.draw.rect(
canvas,
(255, 0, 0),
pygame.Rect(
pix_square_size * self._target_location,
(pix_square_size, pix_square_size),
),
)
# Now we draw the agent
pygame.draw.circle(
canvas,
(0, 0, 255),
(self._agent_location + 0.5) * pix_square_size,
pix_square_size / 3,
)
# Finally, add some gridlines
for x in range(self.size + 1):
pygame.draw.line(
canvas,
0,
(0, pix_square_size * x),
(self.window_size, pix_square_size * x),
width=3,
)
pygame.draw.line(
canvas,
0,
(pix_square_size * x, 0),
(pix_square_size * x, self.window_size),
width=3,
)
if self.render_mode == "human":
# The following line copies our drawings from `canvas` to the visible window
self.window.blit(canvas, canvas.get_rect())
pygame.event.pump()
pygame.display.update()
# We need to ensure that human-rendering occurs at the predefined framerate.
# The following line will automatically add a delay to keep the framerate stable.
self.clock.tick(self.metadata["render_fps"])
else: # rgb_array
return np.transpose(
np.array(pygame.surfarray.pixels3d(canvas)), axes=(1, 0, 2)
)
關閉¶
close 方法應關閉環境使用的任何開啟的資源。在許多情況下,您實際上不必費心實作此方法。但是,在我們的範例中,render_mode 可能是 "human",我們可能需要關閉已開啟的視窗
def close(self):
if self.window is not None:
pygame.display.quit()
pygame.quit()
在其他環境中,close 也可能關閉已開啟的檔案或釋放其他資源。在呼叫 close 後,您不應與環境互動。
註冊環境¶
為了讓 Gymnasium 偵測到自訂環境,必須按如下方式註冊它們。我們將選擇將此程式碼放在 gymnasium_env/__init__.py 中。
from gymnasium.envs.registration import register
register(
id="gymnasium_env/GridWorld-v0",
entry_point="gymnasium_env.envs:GridWorldEnv",
)
環境 ID 由三個組件組成,其中兩個是可選的:一個可選的命名空間(此處:gymnasium_env)、一個強制性名稱(此處:GridWorld)和一個可選但建議的版本(此處:v0)。它也可能已註冊為 GridWorld-v0(推薦方法)、GridWorld 或 gymnasium_env/GridWorld,然後應在環境建立期間使用適當的 ID。
關鍵字參數 max_episode_steps=300 將確保透過 gymnasium.make 實例化的 GridWorld 環境將被封裝在 TimeLimit 封裝器中(有關更多資訊,請參閱 封裝器文件)。然後,如果代理已到達目標或在目前回合中已執行 300 個步驟,則會產生完成訊號。為了區分截斷和終止,您可以檢查 info["TimeLimit.truncated"]。
除了 id 和 entrypoint 之外,您可以將以下額外的關鍵字參數傳遞給 register
名稱 |
類型 |
預設 |
描述 |
|---|---|---|---|
|
|
|
任務被視為已解決之前的獎勵閾值 |
|
|
|
即使在設定種子後,此環境是否仍為非確定性 |
|
|
|
回合可以包含的最大步驟數。如果不是 |
|
|
|
是否將環境封裝在 |
|
|
|
環境類別的預設 kwargs |
這些關鍵字中的大多數(除了 max_episode_steps、order_enforce 和 kwargs 之外)不會改變環境實例的行為,而僅僅提供有關您環境的一些額外資訊。註冊後,可以使用 env = gymnasium.make('gymnasium_env/GridWorld-v0') 建立我們的自訂 GridWorldEnv 環境。
gymnasium_env/envs/__init__.py 應該有
from gymnasium_env.envs.grid_world import GridWorldEnv
如果您的環境未註冊,您可以選擇性地傳遞要匯入的模組,這將在建立環境之前註冊您的環境,如下所示 - env = gymnasium.make('module:Env-v0'),其中 module 包含註冊程式碼。對於 GridWorld 環境,註冊程式碼透過匯入 gymnasium_env 來執行,因此如果無法明確匯入 gymnasium_env,您可以在建立時透過 env = gymnasium.make('gymnasium_env:gymnasium_env/GridWorld-v0') 進行註冊。當您僅被允許將環境 ID 傳遞到第三方程式碼庫(例如,學習函式庫)時,這特別有用。這讓您無需編輯函式庫的原始碼即可註冊您的環境。
建立套件¶
最後一步是將我們的程式碼建構為 Python 套件。這涉及配置 pyproject.toml。以下是如何執行此操作的最小範例
[build-system]
requires = ["hatchling"]
build-backend = "hatchling.build"
[project]
name = "gymnasium_env"
version = "0.0.1"
dependencies = [
"gymnasium",
"pygame==2.1.3",
"pre-commit",
]
建立環境實例¶
現在您可以使用以下命令在本機安裝您的套件
pip install -e .
您可以使用以下方式建立環境的實例
# run_gymnasium_env.py
import gymnasium
import gymnasium_env
env = gymnasium.make('gymnasium_env/GridWorld-v0')
您也可以將環境建構子的關鍵字參數傳遞給 gymnasium.make 以自訂環境。在我們的例子中,我們可以執行
env = gymnasium.make('gymnasium_env/GridWorld-v0', size=10)
有時,您可能會發現跳過註冊並自行呼叫環境的建構子更方便。有些人可能會覺得這種方法更符合 Python 風格,並且像這樣實例化的環境也完全沒問題(但請記住也要新增封裝器!)。
使用封裝器¶
通常,我們想要使用自訂環境的不同變體,或者我們想要修改 Gymnasium 或其他方提供的環境的行為。封裝器允許我們在不更改環境實作或新增任何樣板程式碼的情況下執行此操作。請查看 封裝器文件,以了解有關如何使用封裝器以及實作您自己的封裝器的詳細資訊。在我們的範例中,觀察無法直接在學習程式碼中使用,因為它們是字典。但是,我們實際上不需要修改我們的環境實作來解決這個問題!我們可以簡單地在環境實例之上新增一個封裝器,以將觀察展平為單一陣列
import gymnasium
import gymnasium_env
from gymnasium.wrappers import FlattenObservation
env = gymnasium.make('gymnasium_env/GridWorld-v0')
wrapped_env = FlattenObservation(env)
print(wrapped_env.reset()) # E.g. [3 0 3 3], {}
封裝器的主要優點是它們使環境高度模組化。例如,您可以只查看目標和代理的相對位置,而不是展平 GridWorld 的觀察。在關於 ObservationWrappers 的章節中,我們實作了一個執行此工作的封裝器。此封裝器也位於 gymnasium_env/wrappers/relative_position.py 中
import gymnasium
import gymnasium_env
from gymnasium_env.wrappers import RelativePosition
env = gymnasium.make('gymnasium_env/GridWorld-v0')
wrapped_env = RelativePosition(env)
print(wrapped_env.reset()) # E.g. [-3 3], {}