


基本用法¶
Gymnasium 是一個專案,為所有單一智能體強化學習環境提供 API(應用程式介面),並實作了常見的環境:cartpole、pendulum、mountain-car、mujoco、atari 等等。本頁將概述如何使用 Gymnasium 的基礎知識,包括其四個主要函數:make()、Env.reset()、Env.step() 和 Env.render()。
Gymnasium 的核心是 Env,這是一個高階 Python 類別,代表來自強化學習理論的馬可夫決策過程 (MDP)(注意:這不是完美的重建,缺少 MDP 的幾個組件)。此類別為使用者提供產生初始狀態、轉換/移動到給定動作的新狀態以及可視化環境的能力。除了 Env 之外,還提供了 Wrapper 來協助擴增/修改環境,特別是智能體的觀察、獎勵和採取的動作。
初始化環境¶
在 Gymnasium 中初始化環境非常容易,可以透過 make() 函數完成
import gymnasium as gym
env = gym.make('CartPole-v1')
此函數將返回一個 Env,供使用者與之互動。若要查看您可以建立的所有環境,請使用 pprint_registry()。此外,make() 提供了許多額外參數,用於指定環境的關鍵字、新增更多或更少的 wrappers 等。有關更多資訊,請參閱 make()。
與環境互動¶
在強化學習中,如下圖所示的經典「智能體-環境迴圈」是智能體和環境如何相互作用的簡化表示。智能體接收有關環境的觀察,然後智能體選擇一個動作,環境使用該動作來確定獎勵和下一個觀察。然後循環重複自身,直到環境結束(終止)。
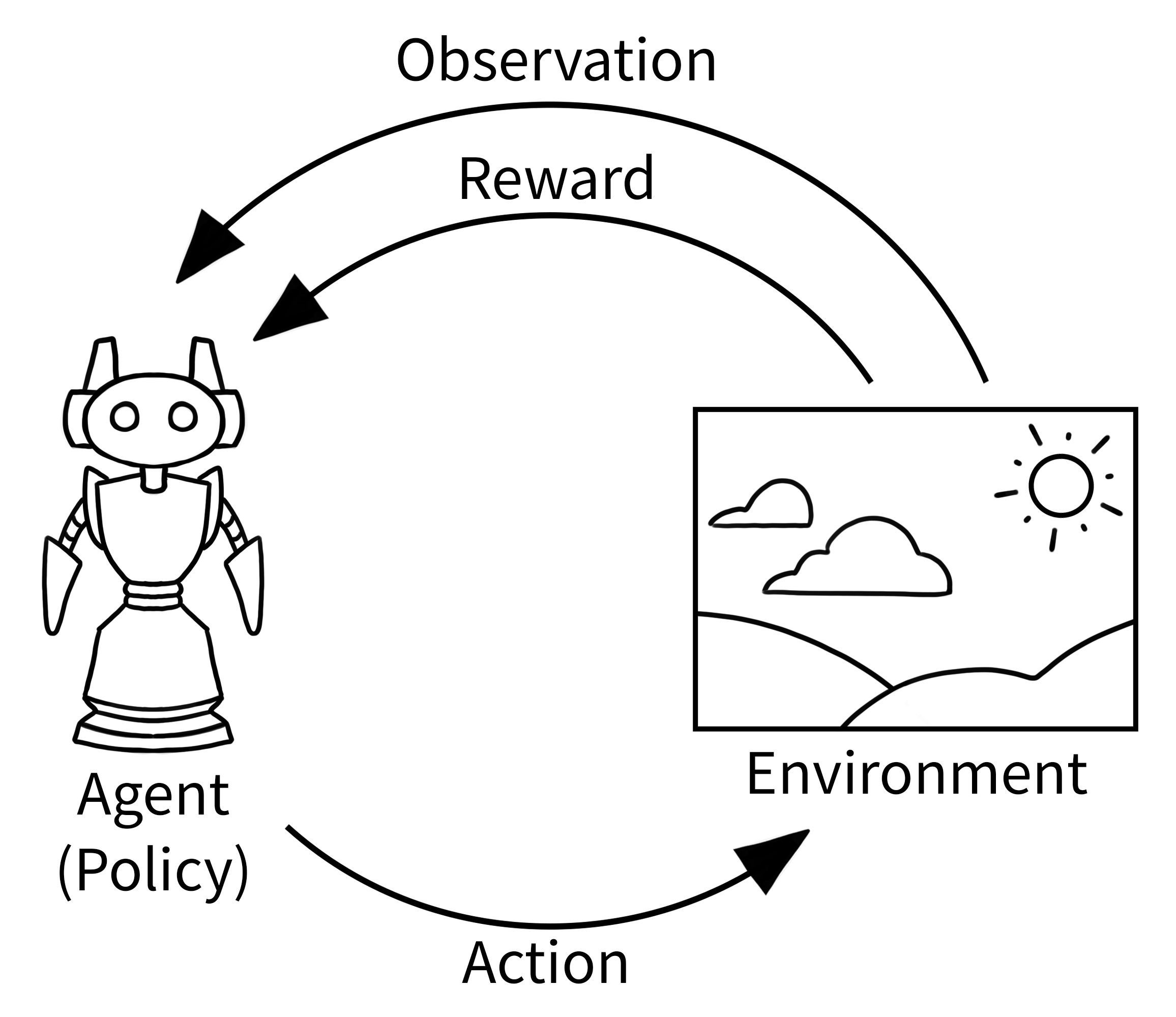
對於 Gymnasium,下文針對單個 episode(直到環境結束)實作了「智能體-環境-迴圈」。有關逐行說明,請參閱下一節。請注意,執行此程式碼需要安裝 swig (pip install swig 或 download) 以及 pip install "gymnasium[box2d]"。
import gymnasium as gym
env = gym.make("LunarLander-v3", render_mode="human")
observation, info = env.reset()
episode_over = False
while not episode_over:
action = env.action_space.sample() # agent policy that uses the observation and info
observation, reward, terminated, truncated, info = env.step(action)
episode_over = terminated or truncated
env.close()
輸出應如下所示

程式碼說明¶
首先,使用 make() 建立環境,並帶有一個額外的關鍵字 "render_mode",用於指定環境應如何可視化。有關不同渲染模式的預設含義的詳細資訊,請參閱 Env.render()。在本範例中,我們使用 "LunarLander" 環境,其中智能體控制一個需要安全著陸的太空船。
初始化環境後,我們 Env.reset() 環境以取得環境的首次觀察以及額外資訊。若要使用特定的隨機種子或選項初始化環境(有關可能的值,請參閱環境文件),請將 seed 或 options 參數與 reset() 一起使用。
由於我們希望繼續智能體-環境迴圈直到環境結束,這在未知數量的時間步長中,我們將 episode_over 定義為一個變數,以了解何時停止與環境互動,以及使用它的 while 迴圈。
接下來,智能體在環境中執行一個動作,Env.step() 執行選定的動作(在本例中,使用 env.action_space.sample() 隨機)以更新環境。此動作可以想像成移動機器人或按下遊戲控制器的按鈕,從而在環境中引起變化。因此,智能體會從更新後的環境接收到新的觀察結果,以及執行該動作的獎勵。例如,此獎勵可能是摧毀敵人的正向獎勵,或是移動到熔岩中的負向獎勵。一個這樣的動作-觀察交換稱為時間步長。
但是,在某些時間步長之後,環境可能會結束,這稱為終止狀態。例如,機器人可能已崩潰,或者可能已成功完成任務,由於智能體無法繼續,因此環境將需要停止。在 Gymnasium 中,如果環境已終止,則由 step() 作為第三個變數 terminated 返回。同樣地,我們也可能希望環境在固定數量的時間步長後結束,在這種情況下,環境會發出截斷訊號。如果 terminated 或 truncated 中的任一項為 True,則我們結束 episode,但在大多數情況下,使用者可能希望重新啟動環境,這可以使用 env.reset() 完成。
動作和觀察空間¶
每個環境都使用 action_space 和 observation_space 屬性指定有效動作和觀察結果的格式。這有助於了解環境的預期輸入和輸出,因為所有有效的動作和觀察結果都應包含在其各自的空間內。在上面的範例中,我們透過 env.action_space.sample() 而不是使用智能體策略(將觀察結果映射到使用者想要採取的動作)來取樣隨機動作。
重要的是,Env.action_space 和 Env.observation_space 是 Space 的實例,這是一個高階 Python 類別,提供關鍵函數:Space.contains() 和 Space.sample()。Gymnasium 支援使用者可能需要的各種空間
Box:描述具有任何 n 維形狀的上限和下限的有界空間。Discrete:描述一個離散空間,其中{0, 1, ..., n-1}是我們的觀察或動作可以採用的可能值。MultiBinary:描述任何 n 維形狀的二元空間。MultiDiscrete:由一系列Discrete動作空間組成,每個元素中的動作數量不同。Text:描述具有最小和最大長度的字串空間。Dict:描述更簡單空間的字典。Tuple:描述簡單空間的元組。Graph:描述具有互連節點和邊緣的數學圖 (網路)。Sequence:描述可變長度的更簡單空間元素。
修改環境¶
Wrappers 是一種修改現有環境的便捷方式,而無需直接更改底層程式碼。使用 wrappers 可以讓您避免大量重複程式碼,並使您的環境更模組化。Wrappers 也可以鏈接以組合其效果。大多數透過 gymnasium.make() 產生的環境預設情況下都已使用 TimeLimit、OrderEnforcing 和 PassiveEnvChecker 進行包裝。
為了包裝環境,您必須先初始化一個基礎環境。然後,您可以將此環境以及(可能可選的)參數傳遞給 wrapper 的建構函數
>>> import gymnasium as gym
>>> from gymnasium.wrappers import FlattenObservation
>>> env = gym.make("CarRacing-v3")
>>> env.observation_space.shape
(96, 96, 3)
>>> wrapped_env = FlattenObservation(env)
>>> wrapped_env.observation_space.shape
(27648,)
Gymnasium 已經為您提供了許多常用的 wrappers。一些範例
TimeLimit:如果超過了最大時間步長數(或基礎環境發出了截斷訊號),則發出截斷訊號。ClipAction:裁剪傳遞給step的任何動作,使其位於基礎環境的動作空間中。RescaleAction:對動作應用仿射變換,以線性縮放環境的新下限和上限。TimeAwareObservation:將有關時間步長索引的資訊新增至觀察結果。在某些情況下,有助於確保轉換是馬可夫性的。
有關 Gymnasium 中已實作的 wrappers 的完整列表,請參閱 wrappers。
如果您有包裝的環境,並且想要取得所有 wrappers 層底下的未包裝環境(以便您可以手動呼叫函數或更改環境的某些底層方面),則可以使用 unwrapped 屬性。如果環境已經是基礎環境,則 unwrapped 屬性只會返回自身。
>>> wrapped_env
<FlattenObservation<TimeLimit<OrderEnforcing<PassiveEnvChecker<CarRacing<CarRacing-v3>>>>>>
>>> wrapped_env.unwrapped
<gymnasium.envs.box2d.car_racing.CarRacing object at 0x7f04efcb8850>