


倒單擺¶
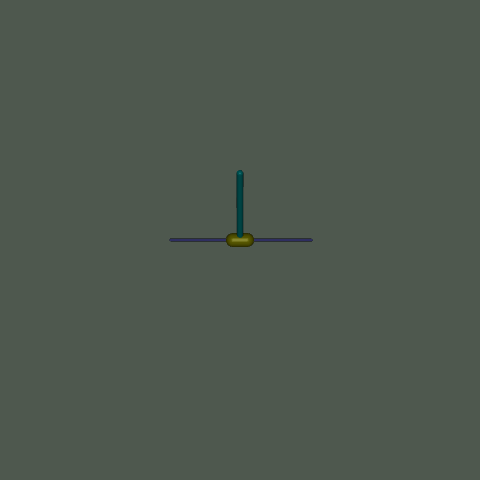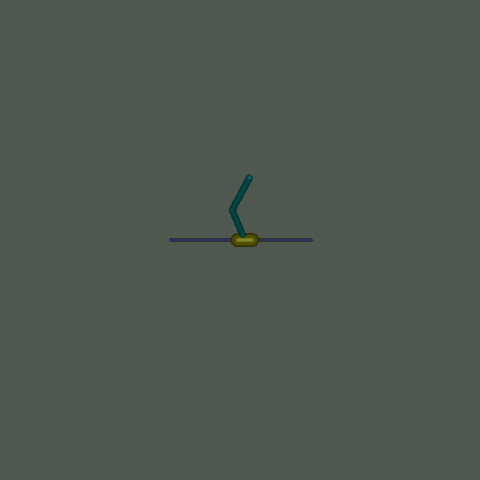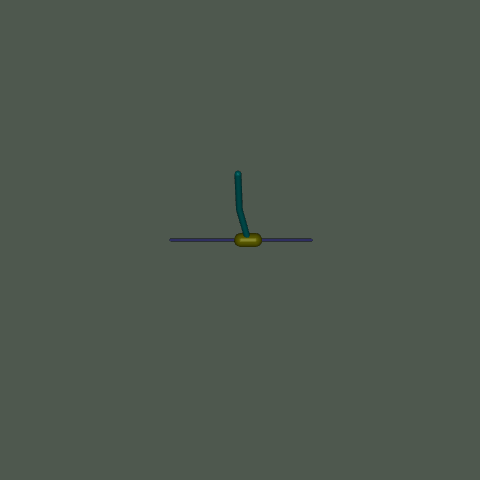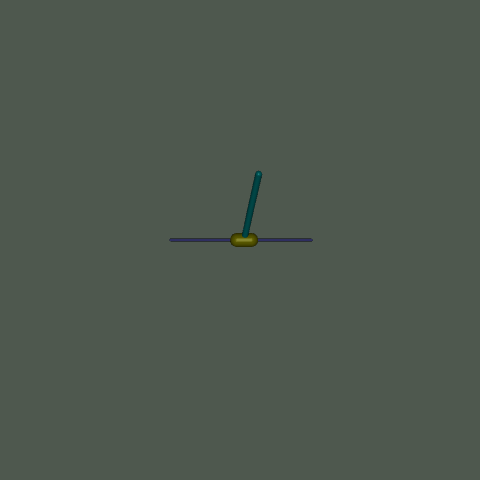
此環境是 Mujoco 環境的一部分,其中包含關於環境的通用資訊。
動作空間 |
|
觀察空間 |
|
import(導入) |
|
描述¶
此環境源自控制理論,並建立在基於 Barto、Sutton 和 Anderson 在 “Neuronlike adaptive elements that can solve difficult learning control problems” 中的工作之上的 cartpole 環境之上,由 Mujoco 物理模擬器驅動 - 允許更複雜的實驗(例如改變重力或約束的效果)。此環境涉及一個可以線性移動的推車,其上連接了一根桿,第二根桿連接到第一根桿的另一端(使第二根桿成為唯一具有自由端的桿)。推車可以向左或向右推動,目標是通過對推車施加連續力來平衡第二根桿在第一根桿頂部,而第一根桿又在推車頂部。
動作空間¶
智能體採用 1 元素向量作為動作。動作空間是連續的 (action),範圍在 [-1, 1] 中,其中 action 代表施加在推車上的數值力(量值代表力的大小,符號代表方向)
編號 |
動作 |
控制最小值 |
控制最大值 |
名稱 (在相應的 XML 檔案中) |
關節 |
類型 (單位) |
|---|---|---|---|---|---|---|
0 |
施加在推車上的力 |
-1 |
1 |
滑桿 |
滑動 |
力 (N) |
觀察空間¶
觀察空間由以下部分組成 (依序)
qpos (1 個元素): 機器人推車的位置值。
sin(qpos) (2 個元素): 桿子角度的正弦值。
cos(qpos) (2 個元素): 桿子角度的餘弦值。
qvel (3 個元素): 這些個別身體部位的速度 (它們的導數)。
qfrc_constraint (1 個元素): 推車的約束力。每個自由度 (3) 的接觸都有一個約束力。MuJoCo 對約束的方法和處理是模擬器獨有的,並且基於他們的研究。更多資訊可以在他們的 文件 或他們的論文 “Analytically-invertible dynamics with contacts and constraints: Theory and implementation in MuJoCo” 中找到。
觀察空間是 Box(-Inf, Inf, (9,), float64),其中元素如下
編號 |
觀察 |
最小值 |
最大值 |
名稱 (在相應的 XML 檔案中) |
關節 |
類型 (單位) |
|---|---|---|---|---|---|---|
0 |
推車沿線性表面的位置 |
-Inf |
Inf |
滑桿 |
滑動 |
位置 (m) |
1 |
推車和第一根桿之間角度的正弦值 |
-Inf |
Inf |
sin(hinge) |
鉸鏈 |
無單位 |
2 |
兩根桿之間角度的正弦值 |
-Inf |
Inf |
sin(hinge2) |
鉸鏈 |
無單位 |
3 |
推車和第一根桿之間角度的餘弦值 |
-Inf |
Inf |
cos(hinge) |
鉸鏈 |
無單位 |
4 |
兩根桿之間角度的餘弦值 |
-Inf |
Inf |
cos(hinge2) |
鉸鏈 |
無單位 |
5 |
推車的速度 |
-Inf |
Inf |
滑桿 |
滑動 |
速度 (m/s) |
6 |
推車和第一根桿之間角度的角速度 |
-Inf |
Inf |
鉸鏈 |
鉸鏈 |
角速度 (rad/s) |
7 |
兩根桿之間角度的角速度 |
-Inf |
Inf |
hinge2 |
鉸鏈 |
角速度 (rad/s) |
8 |
約束力 - x |
-Inf |
Inf |
滑桿 |
滑動 |
力 (N) |
已排除 |
約束力 - y |
-Inf |
Inf |
滑桿 |
滑動 |
力 (N) |
已排除 |
約束力 - z |
-Inf |
Inf |
滑桿 |
滑動 |
力 (N) |
獎勵¶
總獎勵為:獎勵 = 存活獎勵 - 距離懲罰 - 速度懲罰。
存活獎勵:在倒單擺處於健康狀態的每個時間步(請參閱「情節結束」部分中的定義),它都會獲得固定值
healthy_reward的獎勵(預設為 \(10\))。距離懲罰:此獎勵衡量第二根擺錘(唯一的自由端)的尖端移動了多遠,計算方式為 \(0.01 x_{pole2-tip}^2 + (y_{pole2-tip}-2)^2\),其中 \(x_{pole2-tip}, y_{pole2-tip}\) 是第二根桿尖端的 xy 座標。
速度懲罰:一個負獎勵,用於懲罰智能體移動太快。\(10^{-3} \omega_1 + 5 \times 10^{-3} \omega_2\),其中 \(\omega_1, \omega_2\) 是鉸鏈的角速度。
info 包含個別的獎勵項。
起始狀態¶
初始位置狀態為 \(\mathcal{U}_{[-reset\_noise\_scale \times I_{3}, reset\_noise\_scale \times I_{3}]}\)。初始速度狀態為 \(\mathcal{N}(0_{3}, reset\_noise\_scale^2 \times I_{3})\)。
其中 \(\mathcal{N}\) 是多元常態分佈,而 \(\mathcal{U}\) 是多元均勻連續分佈。
情節結束¶
終止¶
當倒單擺不健康時,環境會終止。如果發生以下任何情況,則倒單擺不健康
1.終止:第二根桿尖端的 y 座標 \(\leq 1\)。
注意:當所有部件垂直堆疊在一起時,系統的最大站立高度為 1.2 米。
截斷¶
情節的預設持續時間為 1000 個時間步。
參數¶
InvertedDoublePendulum 提供了多種參數來修改觀察空間、獎勵函數、初始狀態和終止條件。這些參數可以在 gymnasium.make 期間以以下方式應用
import gymnasium as gym
env = gym.make('InvertedDoublePendulum-v5', healthy_reward=10, ...)
參數 |
類型 |
預設值 |
描述 |
|---|---|---|---|
|
str |
|
MuJoCo 模型的路徑 |
|
float |
|
如果擺錘 |
|
float |
|
初始位置和速度的隨機擾動比例(請參閱 |
版本歷史¶
v5
現在最低
mujoco版本為 2.3.3。新增
default_camera_config參數,一個用於設定mj_camera屬性的字典,主要用於自訂環境。新增
frame_skip參數,用於配置dt(step()的持續時間),預設值因環境而異,請查看環境文件頁面。修正錯誤:
healthy_reward在每個步驟都會給予(即使擺錘不健康),現在僅在 DoublePendulum 健康(未終止)時才會給予(相關 GitHub issue)。從觀察空間中排除鉸鏈的
qfrc_constraint(「約束力」)(因為它始終為 0,因此沒有為智能體提供任何有用的資訊,從而略微加快了訓練速度)(相關 GitHub issue)。新增
xml_file參數。新增
reset_noise_scale參數以設定初始狀態的範圍。新增
healthy_reward參數以配置獎勵函數(預設值與v4中的預設值大致相同)。在
info中新增個別獎勵項(info["reward_survive"]、info["distance_penalty"]、info["velocity_penalty"])。
v4:所有 MuJoCo 環境現在都使用 mujoco >= 2.1.3 中的 MuJoCo 綁定。
v3:此環境沒有 v3 版本。
v2:所有連續控制環境現在都使用 mujoco-py >= 1.50。
v1:對於基於機器人的任務(包括倒單擺),max_time_steps 提高到 1000。
v0:初始版本發佈。