


桿子與車¶
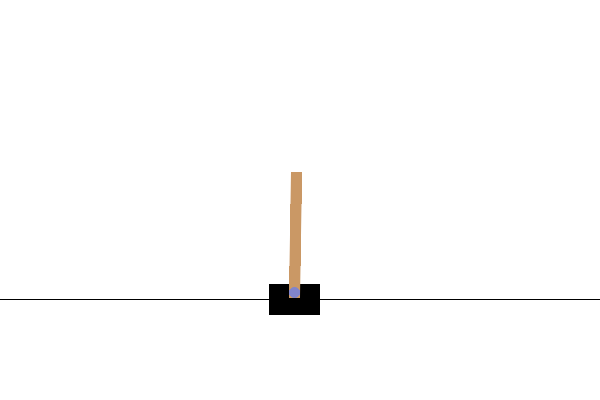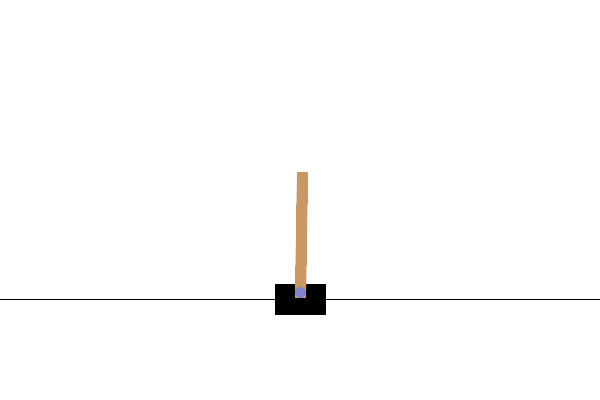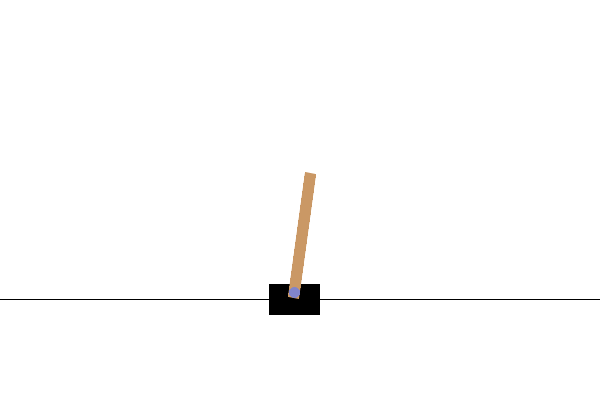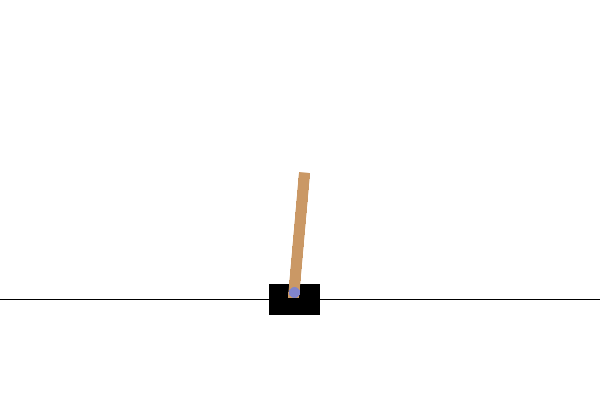
此環境是經典控制環境的一部分,其中包含關於環境的一般資訊。
動作空間 |
|
觀測空間 |
|
import |
|
描述¶
此環境對應於 Barto、Sutton 和 Anderson 在「Neuronlike Adaptive Elements That Can Solve Difficult Learning Control Problem」中描述的桿子與車問題版本。桿子通過一個非致動關節連接到一個沿無摩擦軌道移動的車子上。鐘擺垂直放置在車子上,目標是通過在車子上向左和向右施加力來平衡桿子。
動作空間¶
動作是一個形狀為 (1,) 的 ndarray,它可以取值 {0, 1},表示車子被推動的固定力的方向。
0:向左推車子
1:向右推車子
注意:由施加力減少或增加的速度不是固定的,它取決於桿子指向的角度。桿子的重心會改變將車子移動到其下方所需的能量。
觀測空間¶
觀測是一個形狀為 (4,) 的 ndarray,其值對應於以下位置和速度
編號 |
觀測 |
最小值 |
最大值 |
|---|---|---|---|
0 |
車子位置 |
-4.8 |
4.8 |
1 |
車子速度 |
-Inf |
Inf |
2 |
桿子角度 |
~ -0.418 弧度 (-24°) |
~ 0.418 弧度 (24°) |
3 |
桿子角速度 |
-Inf |
Inf |
注意: 雖然上面的範圍表示每個元素的觀測空間的可能值,但它並不能反映未終止回合中狀態空間的允許值。特別是
車子的 x 位置(索引 0)可以取
(-4.8, 4.8)之間的值,但如果車子離開(-2.4, 2.4)範圍,則回合終止。桿子角度可以在
(-.418, .418)弧度(或 ±24°)之間觀察到,但如果桿子角度不在(-.2095, .2095)(或 ±12°)範圍內,則回合終止
獎勵¶
由於目標是盡可能長時間保持桿子直立,因此預設情況下,對於採取的每個步驟(包括終止步驟),都會給予 +1 的獎勵。由於環境的時間限制,v1 的預設獎勵閾值為 500,v0 的預設獎勵閾值為 200。
如果 sutton_barto_reward=True,則對於每個非終止步驟獎勵 0,對於終止步驟獎勵 -1。因此,v0 和 v1 的獎勵閾值為 0。
起始狀態¶
所有觀測都被分配一個 (-0.05, 0.05) 範圍內的均勻隨機值
回合結束¶
如果發生以下任一情況,回合結束
終止:桿子角度大於 ±12°
終止:車子位置大於 ±2.4(車子的中心到達顯示器的邊緣)
截斷:回合長度大於 500(v0 為 200)
引數¶
Cartpole 僅將 render_mode 作為 gymnasium.make 的關鍵字。在重置時,options 參數允許使用者更改用於確定新隨機狀態的邊界。
>>> import gymnasium as gym
>>> env = gym.make("CartPole-v1", render_mode="rgb_array")
>>> env
<TimeLimit<OrderEnforcing<PassiveEnvChecker<CartPoleEnv<CartPole-v1>>>>>
>>> env.reset(seed=123, options={"low": -0.1, "high": 0.1}) # default low=-0.05, high=0.05
(array([ 0.03647037, -0.0892358 , -0.05592803, -0.06312564], dtype=float32), {})
參數 |
類型 |
預設值 |
描述 |
|---|---|---|---|
|
bool |
|
如果 |
向量化環境¶
為了增加每秒步數,使用者可以使用自訂向量環境或環境向量化器。
>>> import gymnasium as gym
>>> envs = gym.make_vec("CartPole-v1", num_envs=3, vectorization_mode="vector_entry_point")
>>> envs
CartPoleVectorEnv(CartPole-v1, num_envs=3)
>>> envs = gym.make_vec("CartPole-v1", num_envs=3, vectorization_mode="sync")
>>> envs
SyncVectorEnv(CartPole-v1, num_envs=3)
版本歷史¶
v1:
max_time_steps提高到 500。在 Gymnasium
1.0.0a2中,新增了sutton_barto_reward引數(相關 GitHub 問題)
v0:初始版本發佈。